Более половины данных, используемых в системах искусственного интеллекта для здравоохранения, поступает из США и Китая

Многие надеются, что недорогие системы на основе искусственного интеллекта (artificial intelligence, AI) помогут сократить разрыв в оказании медицинской помощи в странах с ограниченными ресурсами. Однако новое исследование показывает, что именно эти страны наименее представлены в данных, используемых для разработки и тестирования большинства клинических AI-систем, что потенциально может сделать эти пробелы еще более значительными.
Исследователи показали, что инструменты на основе AI часто не оправдывают себя при использовании в реальных больницах. Это проблема переносимости - алгоритм, обученный на одной популяции пациентов с определенным набором характеристик, не обязательно будет хорошо работать на другой. Эти неудачи послужили причиной растущего призыва к тому, чтобы клинический AI обучался и проверялся на разнообразных данных о пациентах, где представлены пол, возраст, раса, этническая принадлежность и многое другое.
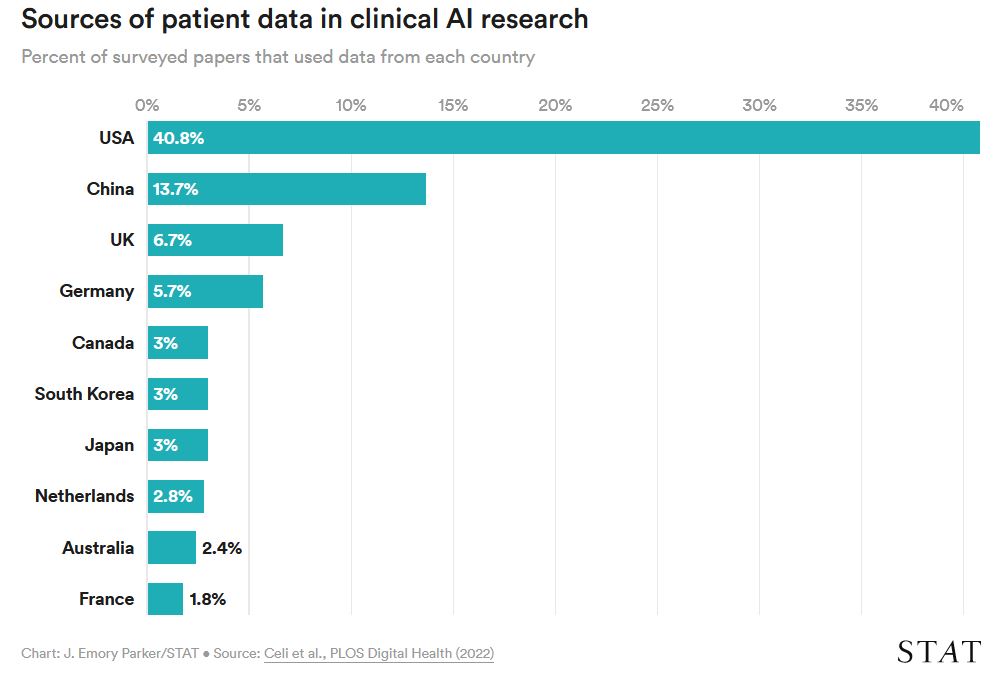
Однако структура глобальных инвестиций в исследования означает, что даже если отдельные ученые стараются представить широкий спектр пациентов, в целом в этой области наблюдается значительный перекос в сторону нескольких национальностей. В ходе анализа более 7000 работ по клиническому AI, опубликованных в 2019 году, исследователи обнаружили, что более половины баз данных, использованных в работе, были получены из США и Китая, а страны с высоким уровнем дохода составляли большинство оставшихся наборов данных пациентов.
Наибольшее беспокойство сейчас вызывает то, что создаваемые алгоритмы принесут пользу только тому населению, которое вносит свой вклад в набор данных. И ничто из этого не будет иметь никакой ценности для тех, кто несет самое большое бремя болезней в этой стране или в мире.
Перекос в данных о пациентах не является неожиданным, учитывая доминирование Китая и Америки в инфраструктуре машинного обучения и исследованиях. Исследование также показало, что на долю китайских и американских исследователей приходится более 40% работ по клиническому AI, если судить по национальной принадлежности первых и последних авторов. Неудивительно, что исследователи тяготеют к данным пациентов, которые находятся ближе всего - и к которым легче всего получить доступ.
Однако риск, связанный с глобальным перекосом в представлении пациентов, заставляет обратить внимание на эти укоренившиеся тенденции, утверждают авторы. Врачи знают, что алгоритмы могут работать по-разному в соседних больницах, обслуживающих разные контингенты пациентов. Они могут даже терять свою силу со временем в одной и той же больнице, поскольку тонкие изменения в практике изменяют данные, которые поступают в систему.
Рекомендации врачей уже адаптированы к странам с хорошими ресурсами, а отсутствие разнообразных данных о пациентах только усугубляет глобальное неравенство в области здравоохранения.
По словам ученых, количественная оценка международного перекоса в исследованиях AI позволит
нам не ограничиваться словами "все очень плохо". Группа надеется использовать это в качестве базового
уровня, по которому можно будет оценивать улучшения. Первый шаг к решению проблемы - ее измерение.
![]()